SDSC and IceCube Center Conduct GPU Cloudburst Experiment
By: Jan Zverina [email protected]
November 22, 2019
The San Diego Supercomputer Center (SDSC) and the Wisconsin IceCube Particle Astrophysics Center (WIPAC) at the University of Wisconsin–Madison successfully completed a computational experiment as part of a multi-institution collaboration that marshalled all globally available for sale GPUs (graphics processing units) across Amazon Web Services, Microsoft Azure, and the Google Cloud Platform.
In all, some 51,500 GPU processors were used during the approximately 2-hour experiment conducted on November 16 and funded under a National Science Foundation EAGER grant. The experiment used simulations from the IceCube Neutrino Observatory, an array of some 5,160 optical sensors deep within a cubic kilometer of ice at the South Pole. In 2017, researchers at the NSF-funded observatory found the first evidence of a source of high-energy cosmic neutrinos – subatomic particles that can emerge from their sources and pass through the universe unscathed, traveling for billions of light years to Earth from some of the most extreme environments in the universe.
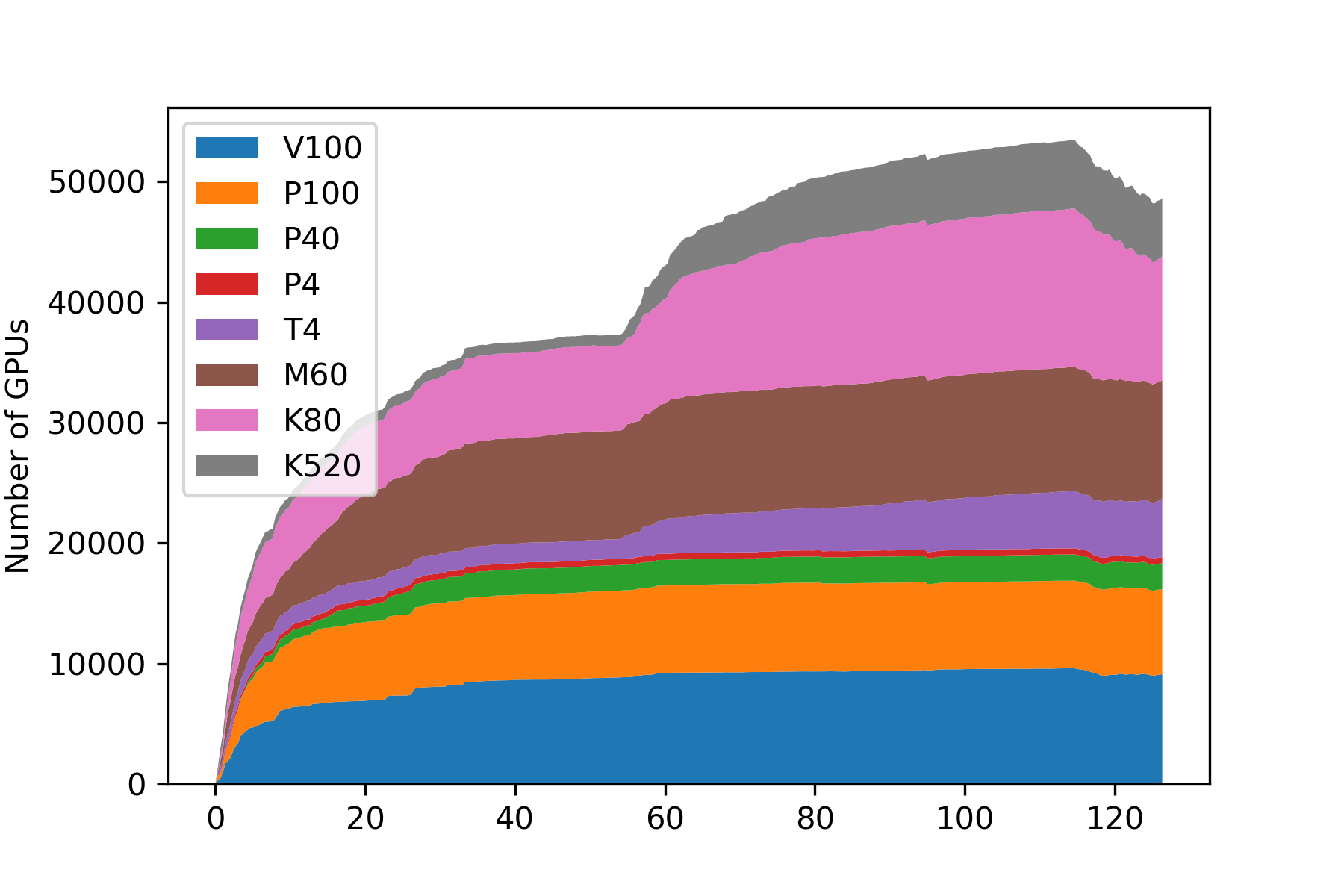
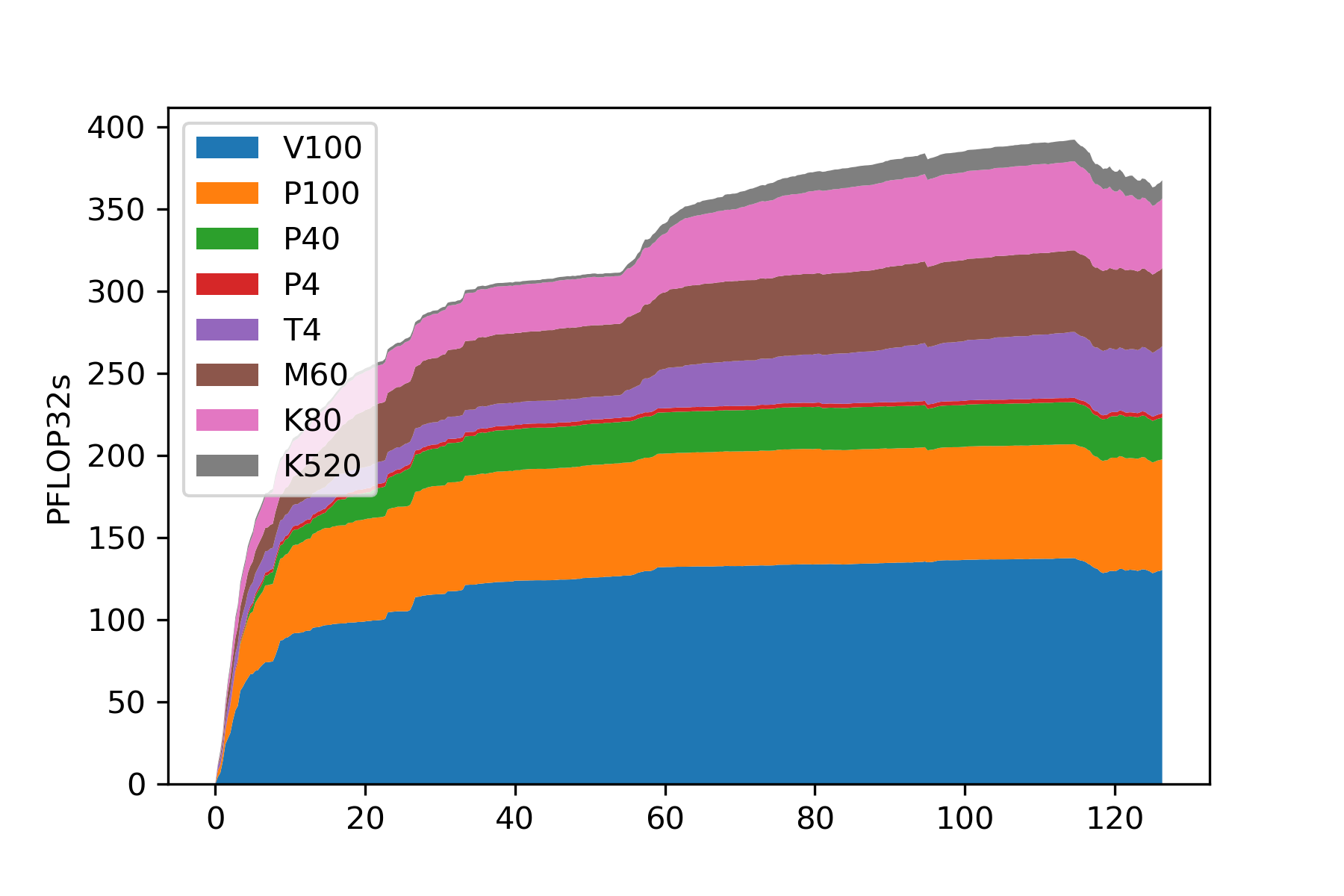
The experiment – completed just prior to the opening of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC19) in Denver, CO – was coordinated by Frank Würthwein, SDSC Lead for High-Throughput Computing, and Benedikt Riedel, Computing Manager for the IceCube Neutrino Observatory and Global Computing Coordinator at WIPAC.
Igor Sfiligoi, SDSC’s lead scientific software developer for high-throughput computing, and David Schultz, a production software manager with IceCube, conducted the actual run.
“We focused this GPU cloud burst in the area of multi-messenger astrophysics, which is based on the observation and analysis of what we call ‘messenger’ signals, in this case neutrinos,” said Würthwein, also a physics professor at the University of California San Diego and Executive Director of the OSG, a multi-disciplinary research partnership specializing in high-throughput computational services funded by the NSF.
“The NSF chose multi messenger astronomy as one of its 10 Big Ideas to focus on during the next few years,” said Würthwein. “We now have instruments that can measure gravitational waves, neutrinos, and various forms of light to see the most violent events in the universe. We’re only starting to understand the physics behind such energetic celestial phenomena that can reach Earth from deepest space.”
The net result was a peak of about 51k GPUs of various kinds, with an aggregate peak of about 380 PFLOP32s (according to NVIDIA specifications), according to Sfiligoi.
| GPU Specs | V100 | P100 | P40 | P4 | T4 | M60 | K80 | K520 |
| Num GPUS | 9.2k | 7.2k | 2.1k | 0.5k | 4.6k | 10.1k | 12.5k | 5.4k |
| PFLOP32s | 132.2 | 68.1 | 25.2 | 2.5 | 38.6 | 48.8 | 51.6 | 12.4 |
“For comparison, the Number 1 TOP100 HPC system, Summit, (based at Oak Ridge National Laboratory) has a nominal performance of about 400 PFLOP32s. So, at peak, our cloud-based cluster provided almost 95% of the performance of Summit, at least for the purpose of IceCube simulations.
The relatively short time span of the experiment showed the ability to conduct a massive amount of data processing within a very short period – an advantage for research projects that must meet a tight deadline. Francis Halzen, principal investigator for IceCube, a Distinguished Professor at the University of Wisconsin–Madison, and director of the university’s Institute for Elementary Particle Physics, foresaw this several years ago.
“We have initiated an effort to improve the calibration of the instrument that will result in sensitivity improved by an estimated factor of four,” wrote Halzen. “We can apply this improvement to 10 years of archived data, thus obtaining the equivalent of 40 years of current IceCube data.”
“We conducted this experiment with three goals in mind,” said IceCube’s Riedel. “One obvious goal was to produce simulations that will be used to do science with IceCube for multi-messenger astrophysics. But we also wanted to understand the readiness of our cyberinfrastructure for bursting into future Exascale-class facilities such as Argonne’s Aurora or Oak Ridge’s Frontier, when they become available. And more generally, we sought to determine how much GPU capacity can be bought today for an hour or so GPU burst in the commercial cloud.”
“This was a social experiment as well,” added Würthwein. “We scavenged up all available GPUs on demand across 28 cloud regions across three continents – North America, Europe, and Asia. The results of this experiment tell us that we can elastically burst to very large scales of GPUs using the cloud, given that exascale computers don’t exist now but may soon be used in the coming years. The demo also shows such bursting of massive data, is suitable for a wide range of challenges across astronomy and other sciences. To the extent that the elasticity is there, we believe that this can be applied across all of scientific research to get results quickly.”
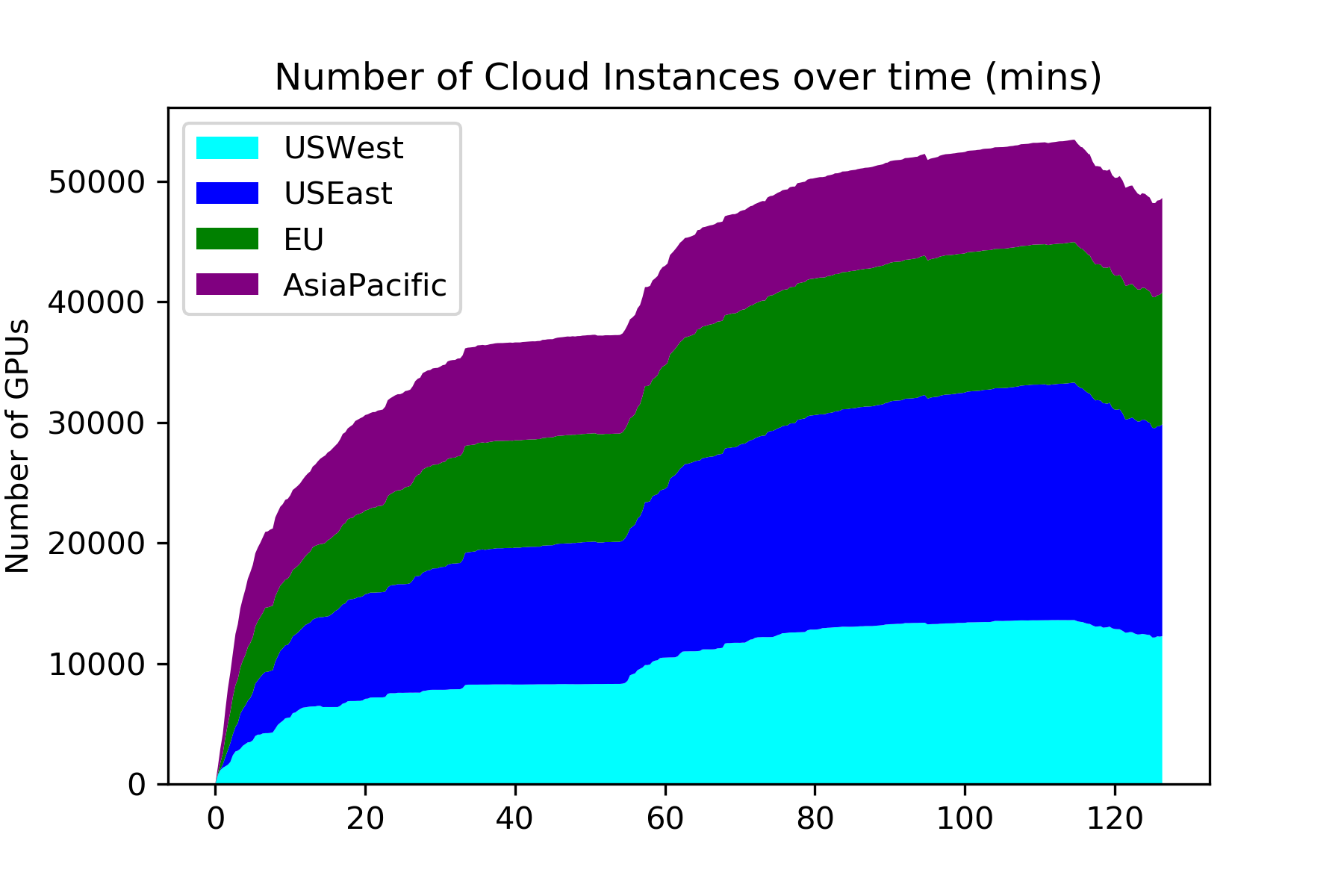
HTCondor was used to integrate all purchased GPUs into a single resource pool to which IceCube submitted their workflows from their home base in Wisconsin. This was accomplished by aggregating resources in each cloud region, and then aggregating those aggregators into a single global pool at SDSC.
“This is very similar to the production infrastructure that OSG operates for IceCube to aggregate dozens of ‘on-prem’ clusters into a single global resource pool across the U.S., Canada, and Europe,” said Sfiligoi.
An additional experiment to reach even higher scales is likely to be made sometime around the Christmas and New Year holidays, when commercial GPU use is traditionally lower, and therefore availability of such GPUs for scientific research is greater.
Acknowledgment: Thanks to the NSF for their support of this endeavor as part of the OAC-1941481, MPS-1148698, OAC-1841530 and OAC-1826967. Special thanks also to all the support personnel from AWS, Azure, Google Cloud and Strategic Blue, who helped raise all the necessary quotas and limits. And all of this would of course not be possible without the hard work of Igor Sfiligoi, David Schultz, Frank Würthwein and Benedikt Riedel.